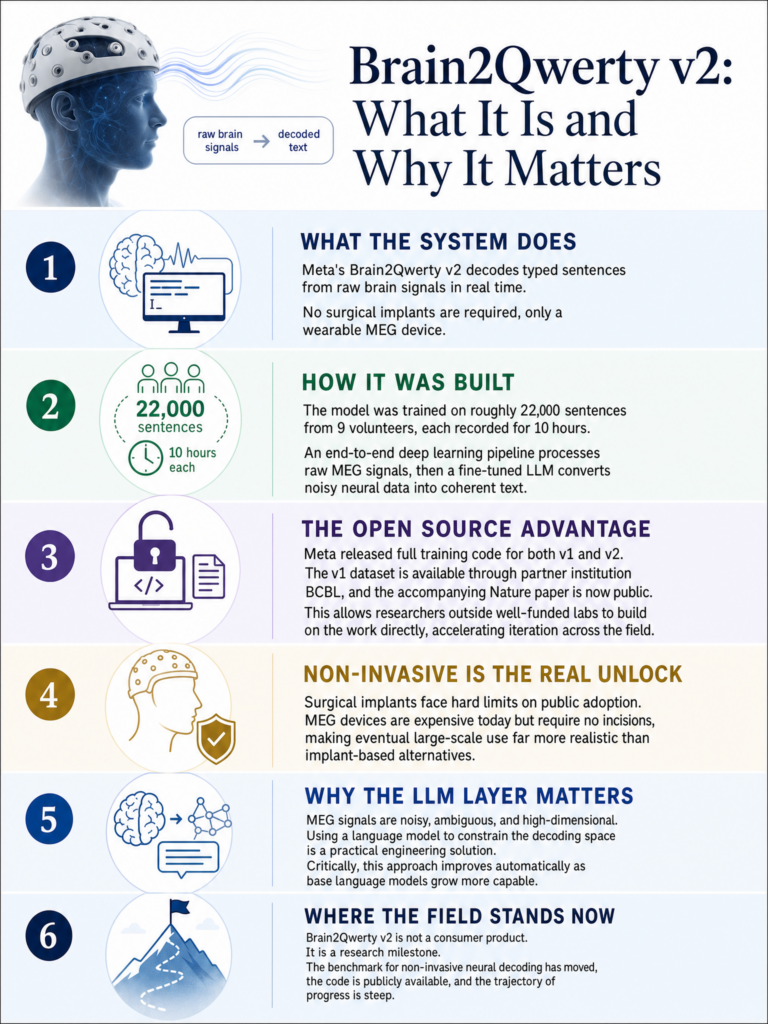
Why structured context at inference time matters more than model size or fine-tuning for real-world AI system performance
Context Is the Moat. Not the Model.
Most teams building AI products are optimizing the wrong thing. They debate model size, chase benchmark scores, and spend weeks on fine-tuning runs. Then they ship something that feels hollow. Generic. Like a customer support bot that clearly has no idea who it’s talking to.
I’ve seen this pattern enough times that I can almost predict it now. The outputs aren’t bad because the model is weak. They’re bad because the model had nothing real to work with.
The Real Problem at Inference Time
Here’s what’s actually happening. When your AI system responds to a user, it draws on two things: what it learned during training, and what you give it at runtime. Training is fixed. You can’t change what the model learned while it’s answering a question. But you can control what context it has access to in that moment.
Most teams treat that runtime context as an afterthought. They write a system prompt, maybe append a few static instructions, and call it a day.
That’s the gap. And it’s where most AI products fall apart.
A concrete example: a customer support AI trained on generic helpdesk data will give you generic helpdesk answers. It doesn’t matter if it’s GPT-4 or a smaller open-weight model. If it doesn’t know this customer has been waiting three weeks for a resolution, has a premium account, and contacted you twice before, it cannot give a useful answer. No amount of fine-tuning on your helpdesk corpus fixes that. Only structured runtime context does.
What “Structured” Actually Means
I’m not talking about dumping a wall of text into the context window and hoping for the best. Structured context means organized, relevant, typed information that the model can reason over. Account state. Recent interactions. Business rules that apply to this specific user in this specific situation.
The difference between unstructured and structured context is the difference between handing someone a filing cabinet and handing someone a briefing document. One requires searching and interpretation. The other enables reasoning.
This is part of why the move toward agent-readable context formats matters so much. Paweł Huryn’s breakdown of Google’s DESIGN.md format (https://x.com/PawelHuryn/status/2034583837351526763) is a useful illustration. The idea there is simple: instead of making an AI agent guess at design intent from scattered documents, you give it a single structured file that tells it exactly what the design system is. The agent doesn’t have to interpret. It can just act.
That same principle applies everywhere AI is doing real work.
Why Fine-Tuning Doesn’t Solve This
Fine-tuning is useful. I’m not dismissing it. But it’s often used to solve a context problem, which is the wrong tool.
Fine-tuning changes the model’s priors. It makes certain response patterns more likely. But it doesn’t give the model access to things that change at runtime: customer state, current inventory, this week’s pricing, the specific conversation thread. You cannot fine-tune a model on your live database. And even if you could embed static business logic through fine-tuning, that logic would be stale the moment anything changed.
What fine-tuning cannot replace is a well-designed context pipeline that fetches, structures, and delivers the right information at the moment of inference.
Anthropic’s recent study of 81,000 Claude users (https://www.anthropic.com) found that the most meaningful uses of AI are deeply tied to personal and professional specificity. People want AI that knows their situation. That’s not a model capability problem. That’s a context delivery problem.
What This Looks Like in Practice
The AI systems I’ve seen actually stick, the ones that get embedded into daily workflows rather than quietly abandoned, share a few traits.
They have a clear retrieval layer that pulls relevant records before generation. They pass that information in a consistent, typed format, not freeform text. And they scope the context tightly: only what’s relevant to this query, not everything the system might theoretically know.
Teams that build this way stop chasing model upgrades as a fix for quality problems. When the context is right, even a mid-tier model produces outputs that feel genuinely useful. When the context is absent, even the best model sounds like it’s guessing.
The Takeaway
If your AI product feels generic, run this check before you touch the model. Ask what structured, current, specific information the model actually had access to when it generated that output.
Most of the time, the answer is “not much.” Fix that first.
The next wave of differentiation in production AI systems won’t come from who has the biggest model. It will come from who built the best context infrastructure around a good-enough one.
Sources & Further Reading
#AIEngineering #MachineLearning #LLMs #ContextEngineering #AIProducts #RAG #MLOps