Mistral OCR 4 launch: bounding boxes, block classification, confidence scores, 72% win rate across 12+ languages
Mistral OCR 4 Is Not an OCR Model. It’s a Document Parser.
There’s a category error happening in how people are talking about Mistral OCR 4. The coverage keeps framing it as a better text extractor. It isn’t. What Mistral shipped is a semantic document parser that happens to read text. That distinction matters a lot if you’re building anything serious on top of unstructured documents.
Let me explain what’s actually different here.
What the Numbers Actually Say
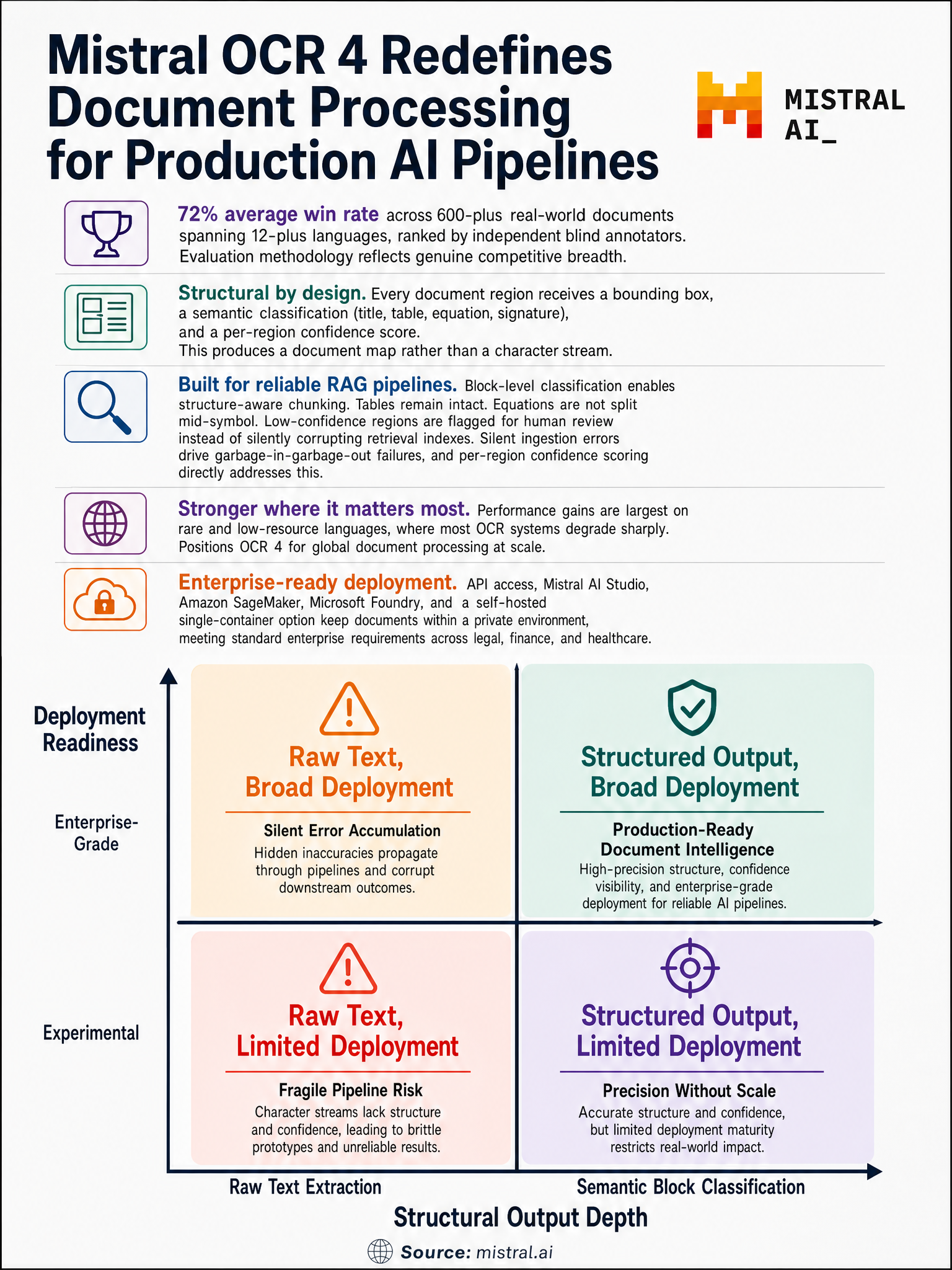
The evaluation Mistral ran was not a standard benchmark. Independent annotators blindly ranked outputs from OCR 4 against every major competitor across 600+ real-world documents in 12+ languages. OCR 4 won 72% of the time on average. Blind annotation, real documents, head-to-head. That’s a methodology with teeth.
On public benchmarks, OCR 4 tops OlmOCRBench with a score of 85.20. The multilingual evaluation shows the widest gains on rare and low-resource languages, which is where most OCR systems quietly fall apart. If your documents aren’t in English or a top-five Western European language, every percentage point on that leaderboard starts to mean something concrete.
The Architecture Shift That Changes Everything
Here’s what OCR 4 actually outputs per document block: a bounding box, a classification label (title, table, equation, signature, and others), and a per-region confidence score. It covers 170 languages total.
That’s three outputs per block, not one. You’re not getting a string of characters. You’re getting a typed, localized, confidence-annotated semantic unit. That is a fundamentally different data structure than what traditional OCR produces, and it changes what you can build on top of it.
Think about what you can do with bounding boxes plus classification plus confidence. You can route low-confidence regions to human review automatically. You can build citation systems that point back to the exact page region, not just the page number. You can redact specific block types (signatures, for instance) without touching surrounding content. You can diff document versions at the block level. None of that is straightforward when your OCR output is a flat wall of text.
Why RAG Builders Should Care
This is where I think OCR 4 does the most work for practitioners right now.
RAG pipeline quality is almost entirely determined by chunking quality. Most teams are doing naive character-limit chunking or sentence-boundary chunking, and it’s genuinely bad. A table gets split mid-row. A section header ends up separated from its content. An equation gets mangled into nonsense tokens. These aren’t edge cases. They’re what happens when you treat a PDF as a text file.
When your chunker knows that block A is a table and block B is a paragraph header and block C is body text, you can make structurally coherent chunks. You can keep tables intact. You can attach headers to their sections. You can skip blocks with confidence scores below a threshold rather than feeding garbage to your embedder.
Chunking quality directly affects retrieval precision, which directly affects answer quality. The semantic map OCR 4 produces is a prerequisite for doing this well, not a nice-to-have.
Deployment and Availability
Mistral made OCR 4 available through their API and Document AI in Mistral AI Studio on launch day. It’s also on Amazon SageMaker and Microsoft Foundry. Snowflake Parse Document support is coming. There’s a self-hosted single-container option for teams that can’t send documents to external APIs. That last one matters for legal, finance, and healthcare use cases where document confidentiality isn’t optional.
What I Think This Signals
Mistral is now 1,000 people. They’ve shipped a model that leads public benchmarks, runs blind evaluations with real-world documents rather than curated test sets, and produces output that fits into modern ML infrastructure rather than legacy ETL pipelines.
The OCR market has been stagnant for years. Most commercial OCR products were built around the assumption that you want text out of an image. Mistral’s bet is that what you actually want is structure out of a document. I think they’re right, and I think teams still pre-processing PDFs with PyMuPDF and a regex cleaner are going to feel that gap widen over the next twelve months.
The question worth asking now is not whether OCR 4 is better at reading text. It clearly is. The question is whether your document pipeline is even designed to consume structured output. If it isn’t, that’s the next thing to fix.
Sources
#RAG #DocumentAI #OCR #MistralAI #MachineLearning #LLM #AIEngineering