
Prediction: voice AI infrastructure will consolidate around single-stack providers faster than text AI did, driven by latency physics
Voice AI Will Consolidate Faster Than Text AI Did. Here’s Why That’s Already Happening.
The text AI market took years to sort itself out. Dozens of API providers, model wrappers, and orchestration layers competed for developer attention, and honestly that competition produced good things. But voice is a different animal, and I think we’re about to watch consolidation happen at a speed that catches most people off guard.
🎙️ The Physics Problem Nobody Talks About Enough
Text generation tolerates latency. You can bolt three different APIs together, add 800ms of overhead per hop, and your users will still read the output just fine. The product ships. The demo works.
Voice doesn’t have that luxury.
A 300ms gap in a spoken conversation is noticeable. At 600ms, it feels broken. Human conversational timing is one of the most deeply conditioned reflexes we have, and no amount of clever UX tricks fixes a pipeline that’s structurally too slow.
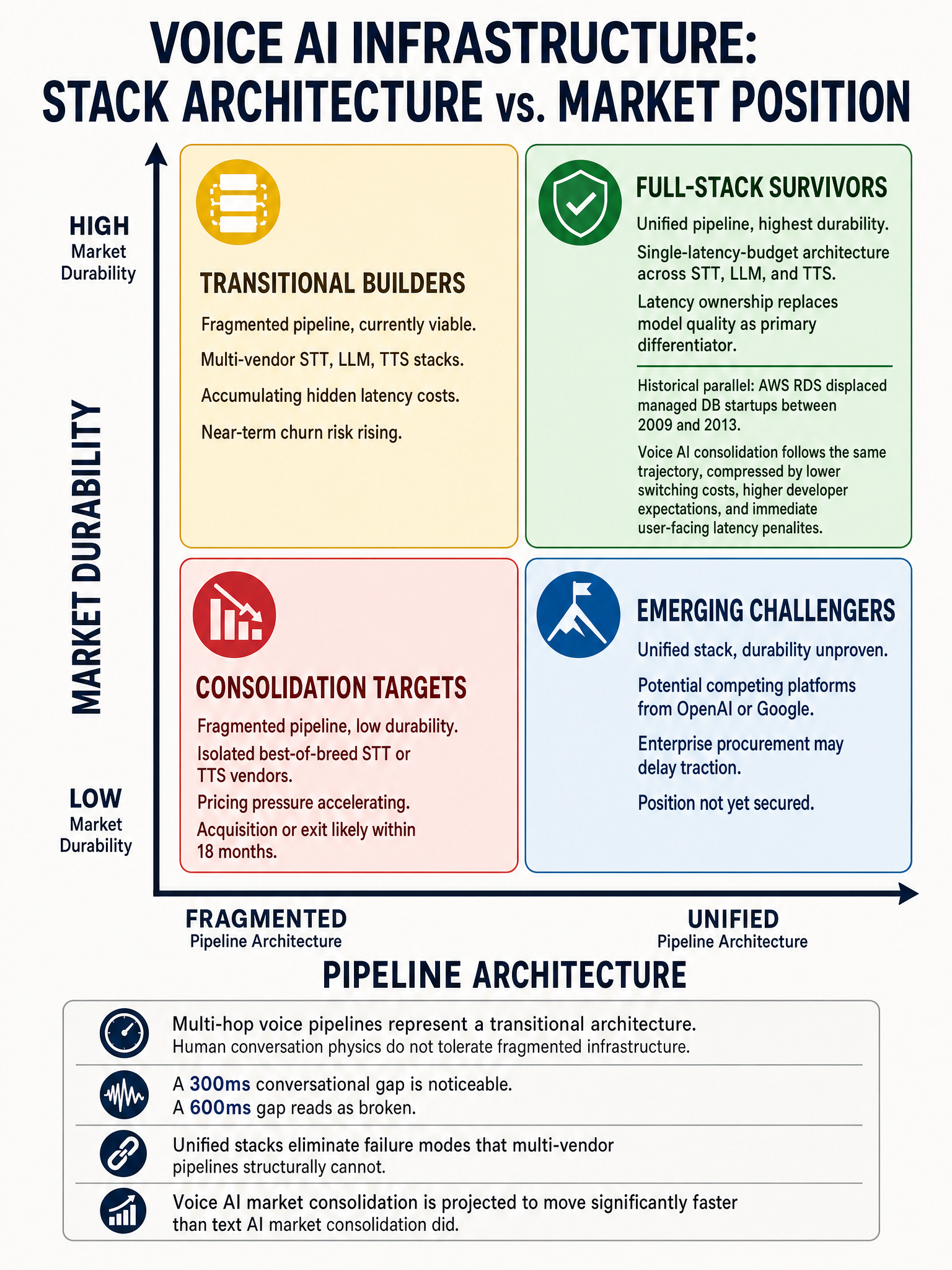
The typical voice stack today looks like this: a speech-to-text provider, a separate LLM call, then a text-to-speech provider. Each of those is a network hop. Each hop has its own failure mode, its own pricing, its own latency floor. You’re not optimizing a pipeline, you’re hoping three independent systems coordinate well enough to feel human.
They don’t. Not reliably.
🔧 What xAI Just Did and Why the Price Is Almost a Distraction
xAI launched Voice Agent Builder this week, a no-code platform for building voice agents on top of Grok Voice, priced at $0.05 per minute. The price got most of the attention. I think that’s the wrong thing to focus on.
What matters is the architecture. As xAI put it directly: “Most voice stacks stitch together three APIs: speech-to-text, a language model, and text-to-speech, often with each stage hosted by a different provider. Every hop adds cost, latency, and new failure modes.”
They’re not wrong, and they’re not just marketing. Unifying STT, LLM, and TTS under a single latency budget is a structural advantage, not a convenience feature. When all three stages run in the same system with shared memory and coordinated timing, you get latency characteristics that a stitched-together pipeline simply cannot match.
The platform ships with telephony, knowledge retrieval, tool use, guardrails, and observability baked in. You can bring your own phone numbers and existing APIs. That’s not a toy, that’s a production-grade pitch to enterprises who are currently paying integration tax on every conversation.
Why Consolidation Happens Faster in Voice
In the text market, differentiation was about quality, context length, cost per token, and fine-tuning options. Those are all things you can mix and match across providers. Developers built abstraction layers, and those layers worked.
In voice, your abstraction layer is the problem. Every millisecond of coordination overhead between providers shows up in the conversation. The developer who stitches together best-of-breed components will consistently lose to the developer running a single coherent stack, not because their components are worse, but because physics doesn’t care about your architecture preferences.
This pushes the market toward single-stack providers faster than text ever did. When the performance gap between integrated and fragmented is audible, customers don’t need a benchmark to feel it.
xAI’s integration into Vercel’s AI Gateway is another data point here. That’s distribution infrastructure, not a research announcement.
What This Means for the Market
I expect the number of credible standalone voice AI providers to shrink significantly over the next 18 months. Not because the technology is hard, though it is, but because the performance ceiling for fragmented pipelines is structurally lower than users will accept.
The companies that survive will be the ones who control the full stack or who get acquired by someone who does. The pure-play STT or TTS providers have a narrowing window to either integrate vertically or find a home inside a larger platform.
At $0.05 per minute, xAI is also signaling that they’re willing to buy market share during the land-grab phase. That’s a familiar move, and it works.
This prediction might feel obvious in 24 months. Right now it still feels early. Build accordingly.
Sources & Further Reading
#VoiceAI #AIInfrastructure #MachineLearning #AIEngineering #BuildingWithAI





