
Anthropic Opus 4.7 matches dedicated NMR spectroscopy software in chemistry tasks
When a General-Purpose Model Beats the Specialists
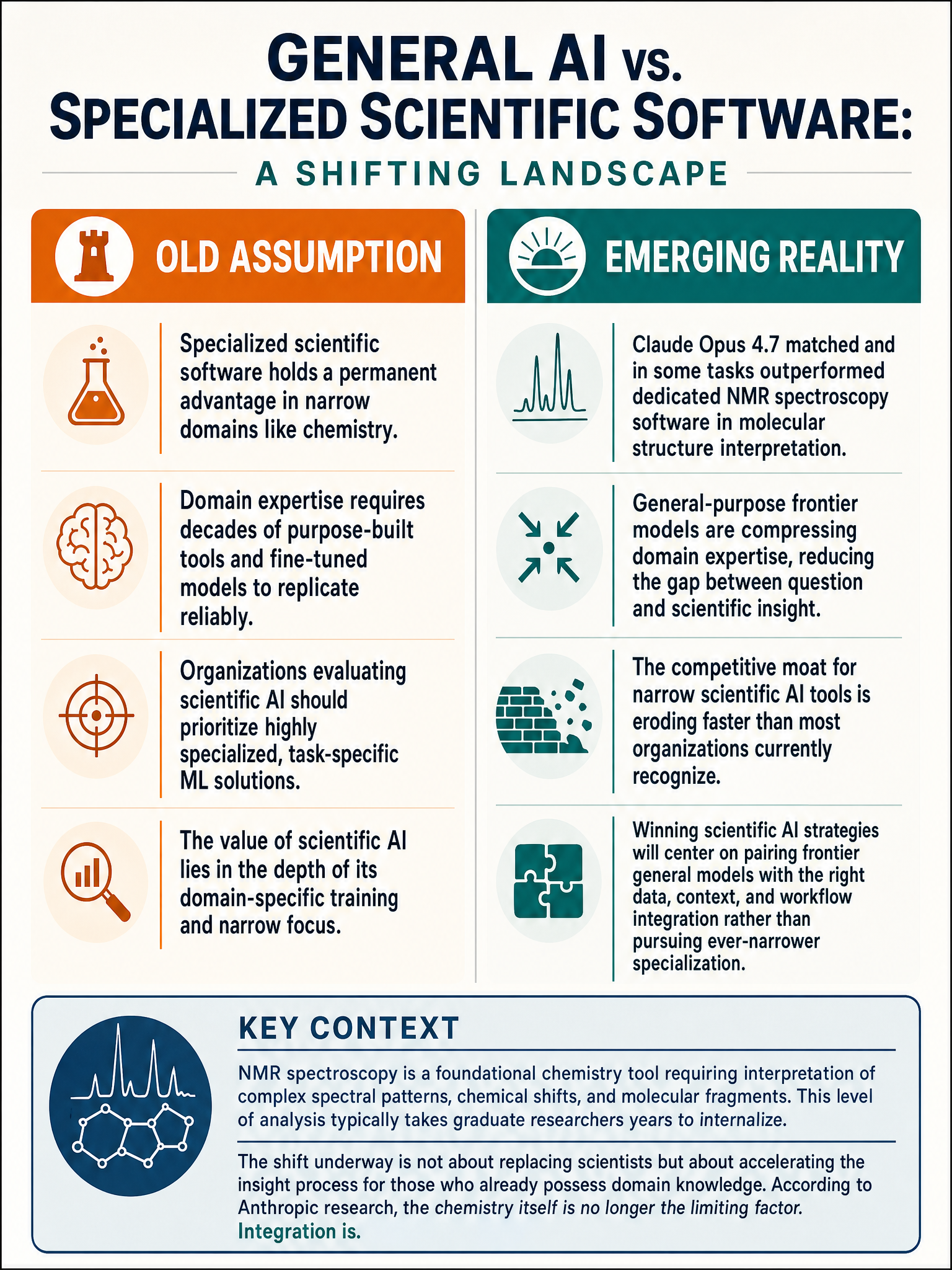
Chemists have a saying: structure is everything. Before you can modify a molecule, synthesize a drug candidate, or understand a reaction mechanism, you need to know what you’re actually looking at. For decades, the tool they’ve relied on for that is NMR spectroscopy. And the software built to interpret NMR spectra is highly specialized, painstakingly tuned, and used by researchers who’ve spent years learning the domain. This week, Anthropic published something that should have gotten more attention: Claude Opus 4.7 matches that software. On some tasks, it beats it.
I want to be precise about why that matters, because it’s easy to read a headline like that and move on.
What NMR Actually Demands
Nuclear magnetic resonance spectroscopy produces complex spectral data that tells you about a molecule’s structure by measuring how atomic nuclei respond to magnetic fields. Interpreting those spectra requires understanding chemical shifts, coupling constants, integration ratios, and how those patterns correspond to specific molecular fragments. Graduate students in organic chemistry spend months, sometimes years, developing fluency with this. Purpose-built software like MestReNova has been trained and refined specifically for this class of problem. It is not a simple task.
So when Anthropic’s Science Blog reports that Opus 4.7 “matches and on some tasks beats dedicated NMR software,” that’s a genuinely surprising result. A model trained on broad text data is competing with a tool that exists for exactly one category of scientific work.
The Broader Pattern Anthropic Is Showing Us
This NMR result doesn’t exist in isolation. Anthropic has been publishing internal data this week that, taken together, suggests something significant is happening with model capability, faster than most people expected.
Their engineers now ship 8x as much code per quarter compared to the 2021 to 2025 baseline. When Anthropic runs their internal benchmark (give the model code that trains a small AI, ask it to speed it up), Claude Opus 4 averaged roughly 3x speedup back in May 2025. Their Mythos Preview model hit 52x this April. On open-ended coding problems where there’s no clean answer, Claude’s success rate jumped 50 percentage points in six months, now sitting at 76%. These are not incremental improvements.
What I find most honest about Anthropic’s framing here is that they’re not overselling it. They explicitly say it’s not yet clear whether Claude can exercise research judgment, meaning choosing the right problems to work on, not just executing on them. That distinction matters enormously and it’s the right place to draw the line for now.
Why “General Purpose” Is Starting to Lose Its Meaning
The NMR result is a useful concrete example of a conceptual shift that’s been happening. The assumption underlying a lot of enterprise software strategy is that specialized tools will always outperform general models in their domain. A purpose-built NMR analysis tool should beat a language model at NMR analysis. That assumption is now in question.
This has real consequences. If a general model can reach specialist-level performance in a domain like NMR interpretation, the economics of scientific software change. The value proposition of narrow tools becomes harder to defend when a foundation model with broad capability can close the gap, especially one that can also explain its reasoning, integrate with other workflows, and iterate conversationally.
I’m not saying specialized tools are dead. There are still domains where deep integration with instrument hardware, proprietary data formats, and decades of domain-specific engineering give purpose-built software advantages that a language model can’t touch. But the margin is shrinking in ways that most vendors probably haven’t priced in.
What This Week Actually Signals
OpenAI introduced GPT-Rosalind this week, a model series built specifically for life sciences research at enterprise scale, combining agentic coding with stronger intelligence for drug discovery and experimental workflows. Google DeepMind’s Co-Scientist is being made available to individual researchers for hypothesis generation. The pattern is consistent: the major labs are all pushing hard into scientific domains at the same time.
The NMR result from Anthropic fits that pattern, but it’s more interesting than a product announcement. It’s an existence proof. A model that wasn’t built to do NMR analysis can now do NMR analysis at the level of software that was. The question that follows from that isn’t really about NMR. It’s about what other specialized domains are next, and how quickly.
Conclusion
The Anthropic Science Blog post is worth reading carefully, not for the headline, but for what it implies about the rate of change in scientific AI capability. Chemistry was supposed to be hard. It is hard. And a general-purpose model is now competitive with the tools chemists built to handle it. If your mental model of AI capability is six months old, it’s probably wrong.
#AI #MachineLearning #Chemistry #ScientificAI #Anthropic #LLM #AIResearch




