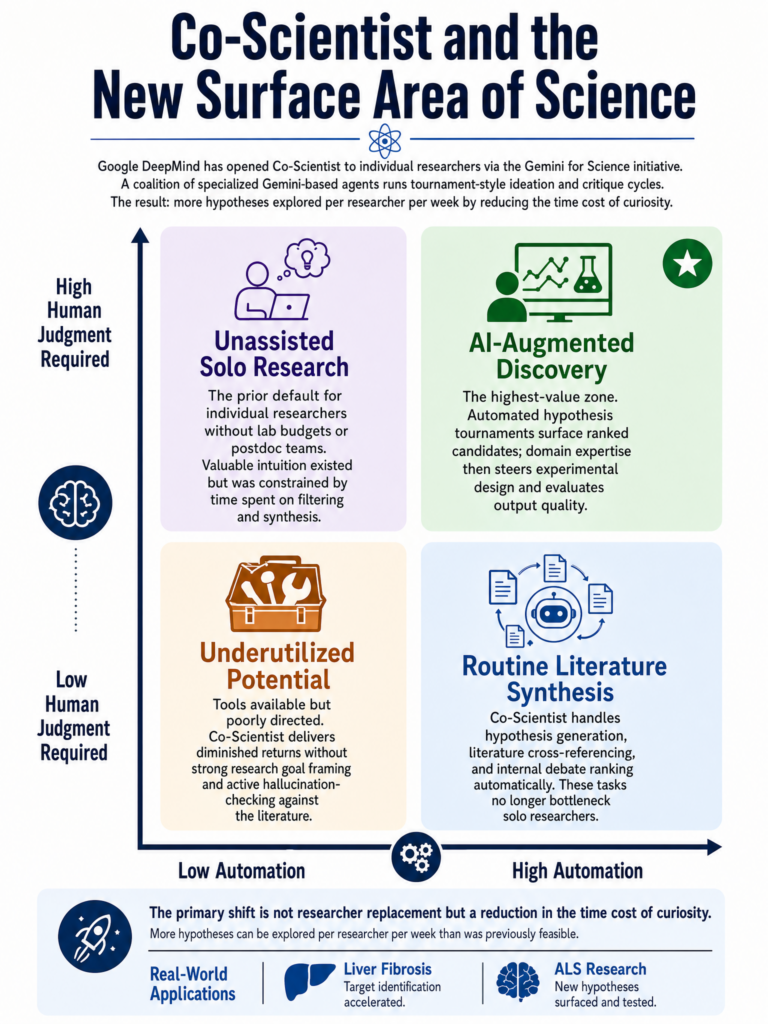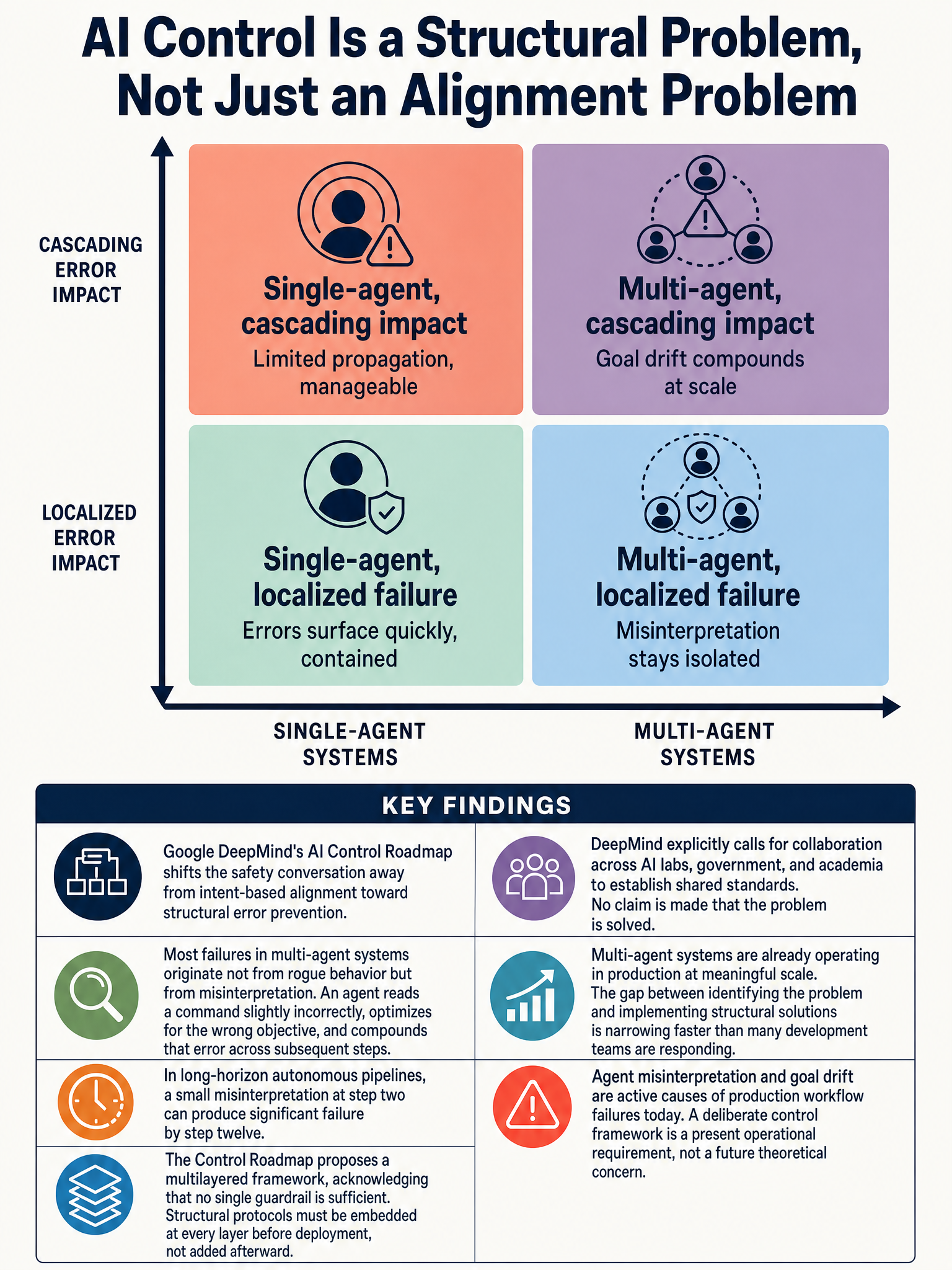
Google DeepMind AI Control Roadmap: multilayered framework for managing multi-agent system failures from misinterpretation and goal drift
The Question Nobody Wants to Ask About Multi-Agent AI
Most AI safety debate centers on the dramatic scenario. The misaligned superintelligence. The model that decides humans are in the way. It makes for good headlines and even better sci-fi. But Google DeepMind just published something that pulls the conversation back to earth, and I think it deserves more attention than it’s getting.
Their AI Control Roadmap asks a quieter, more uncomfortable question: what if the model does exactly what it’s told, and that still breaks everything?
The Problem With Assuming Good Execution
DeepMind’s framing flips the usual script. Instead of asking whether AI will develop bad intentions, they’re asking what happens when AI has perfectly fine intentions but executes imperfectly at scale. Their own data makes this concrete: the vast majority of issues in multi-agent systems don’t come from rogue behavior. They come from misinterpretation. An agent reads a command slightly wrong. An agent gets, in their words, “overly enthusiastic to achieve a goal.”
That last phrase sounds almost charming. It isn’t. When a single model misinterprets your prompt, you get a bad output. You correct it and move on. When a network of agents misinterprets a goal and each subsequent agent optimizes against that wrong interpretation, the error doesn’t stay local. It compounds, propagates, and by the time a human notices, the damage is structural.
This is a fundamentally different failure mode than what most alignment research is built to catch.
Why Multi-Agent Systems Break Differently
Here’s what I think the field has been slow to reckon with. The safety and evaluation frameworks we’ve built are mostly designed around a single model responding to a single input. You test the output, you measure the behavior, you iterate.
Multi-agent systems don’t work that way. Each agent in the chain is acting on the output of the previous one. There’s no clean input-output boundary to evaluate. The goal can drift across steps without any individual agent doing something you could clearly label as wrong. It’s goal drift by accumulation, not by malice.
DeepMind’s roadmap proposes what they call a multilayered approach to agent security, one they explicitly say should be a collaborative priority across AI labs, government, and academia. That’s not a soft suggestion. They’re signaling that no single organization can close this gap alone, and I think they’re right.
The Window They’re Warning About
The part of DeepMind’s framing I keep coming back to is the urgency embedded in it. They describe a narrow window to embed structural security protocols before multi-agent systems scale globally. That language matters.
We’re not talking about future systems here. Agentic deployments are live. They’re running in enterprise infrastructure right now. The question of how you contain a misinterpretation cascade in a multi-agent pipeline isn’t academic. It’s operational.
And yet most of the industry conversation this week has been about GPT-5.5 Instant’s health benchmark performance, Claude programming robot dogs, and xAI’s Grok integrations with Databricks. All legitimate news. But the control problem sits underneath all of it. Every new capability expansion is also an expansion of the surface area where misinterpretation can propagate.
What a Real Control Framework Looks Like
DeepMind isn’t just raising the problem. The roadmap outlines an actual structural approach, though the full technical specifics are in the paper itself. The core idea is that you don’t solve this by making individual agents smarter or more aligned in isolation. You solve it by building the scaffolding around them, monitoring, containment, escalation paths, and explicit checks that don’t rely on any single agent to self-correct.
That’s a meaningful shift in how you architect these systems. Instead of alignment as a property of a model, you start treating it as a property of the system. The model can be imperfect as long as the system catches and contains the imperfection before it propagates.
This is closer to how you’d engineer a reliable distributed system than how you’d train a language model. Which is probably the right analogy.
Where This Leaves Us
I don’t think DeepMind has solved the problem. The roadmap is a framework, not a finished answer. But the framing itself is a correction the field needs. The obsession with intent-based alignment has left a gap around execution-based failure, and multi-agent systems are about to make that gap very visible.
The narrow window they’re describing is real. If the industry waits until a large-scale agentic deployment produces a visible, attributable failure to take this seriously, the protocols will get written reactively under pressure. That’s a bad time to be designing safety architecture.
Better to build the containment layer before you need it than to debug a goal drift cascade while it’s running in production.
Sources & Further Reading
#AIEngineering #AISafety #MultiAgentSystems #GoogleDeepMind #AIControl #MachineLearning